
This is part 7 of a post series about EBR.
Visit the index page for all the parts of the series
Introduction
Our next use case is adding a column that represents a new logic to the PEOPLE table, and making the corresponding changes in the PEOPLE_DL and APP_MGR packages. Of course, as we speak about EBR, the upgrade from the previous version to the new one should be online.
An online upgrade means that the application users should be able to continue working uninterruptedly. The code objects that they use should remain valid and available at any time.
In addition to the challenges raised from the first and second use cases, the current use case introduces another challenge. And unlike the previous challenges, this one cannot be overcome just by using a new edition.
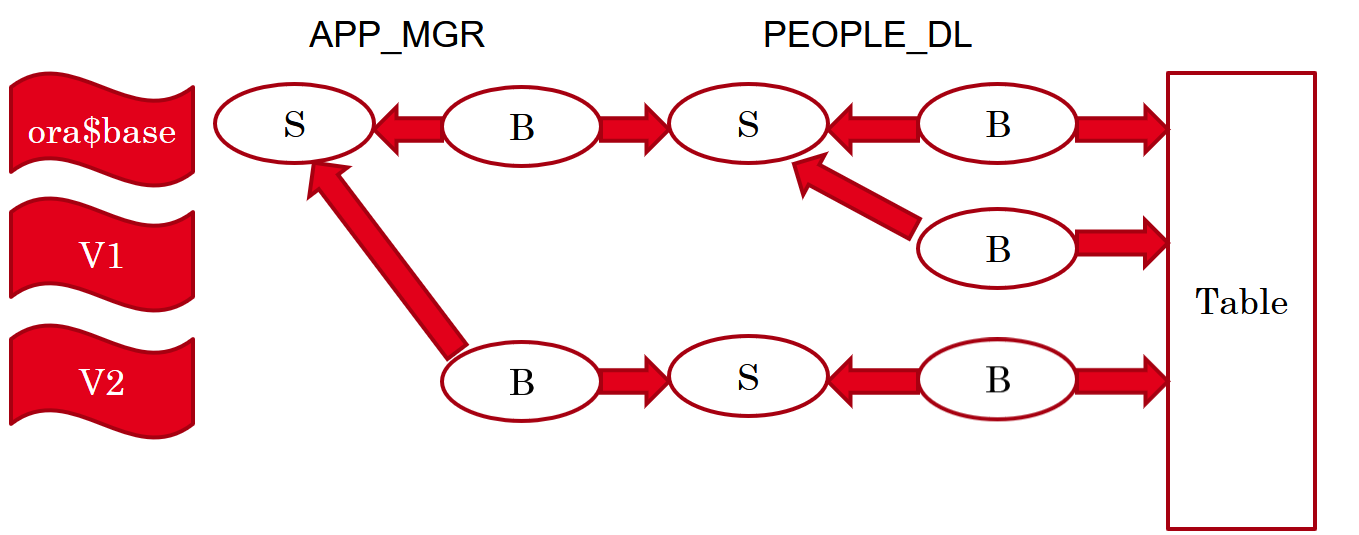
The Current State
At this point, after completing two upgrades already – in part 3 and part 5, we have three editions, with the following actual objects:
V2> select object_name,object_type,status, edition_name
2 from user_objects
3 order by object_name,object_type;
OBJECT_NAME OBJECT_TYPE STATUS EDITION_NAME
------------ ------------ ------- ------------
APP_MGR PACKAGE VALID ORA$BASE
APP_MGR PACKAGE BODY VALID V2
PEOPLE TABLE VALID
PEOPLE_DL PACKAGE VALID V2
PEOPLE_DL PACKAGE BODY VALID V2
PEOPLE_PK INDEX VALID
6 rows selected.
As discussed in part 6, a table is a non-editioned object, and therefore we have a single instance of the PEOPLE table – referenced by all the instances of the PEOPLE_DL package body in all the editions.
The Task
We want to add a new attribute – Eye Color – to the Person entity.
For that we need to add a new column – EYE_COLOR – to the PEOPLE table, add make the corresponding changes in the PEOPLE_DL and APP_MGR packages (adding an input parameter – i_eye_color – to the people_dl.add procedure and changing the implementation of people_dl.add and app_mgr.do_something accordingly).
Our Problem
If we try to add the new column to the table, then Continue reading “EBR – Part 7: Editioning Views”