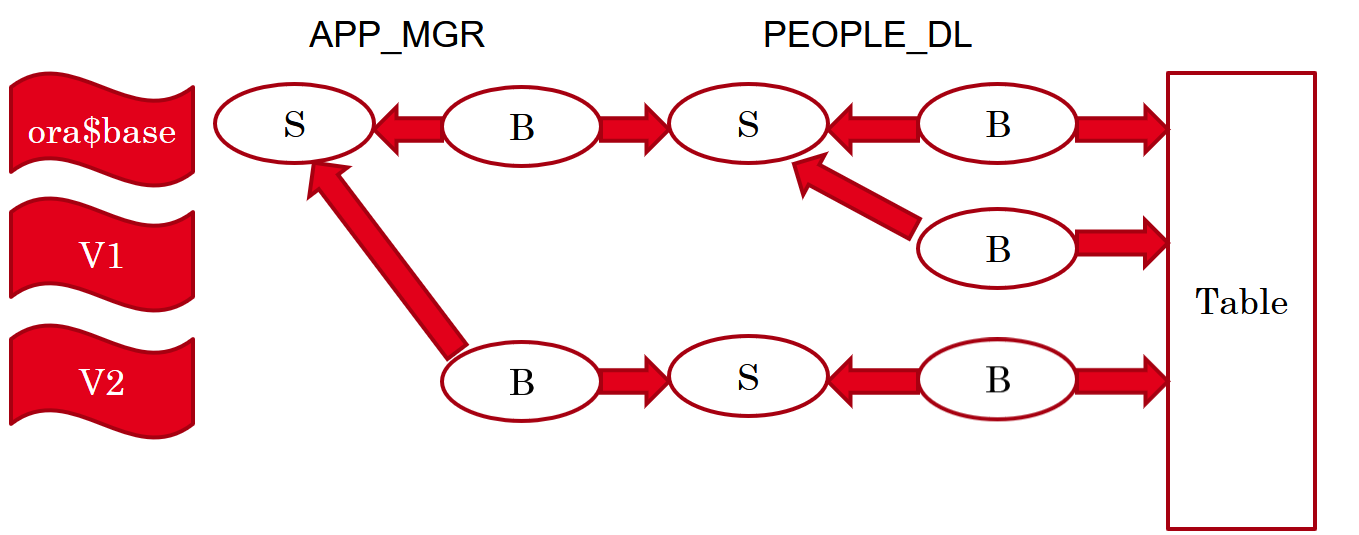
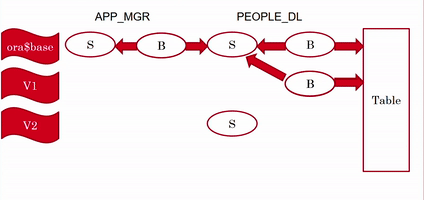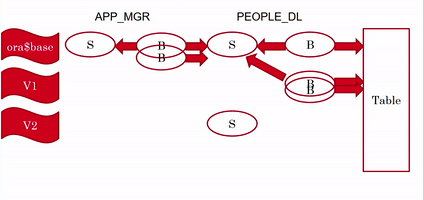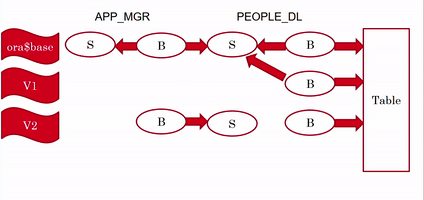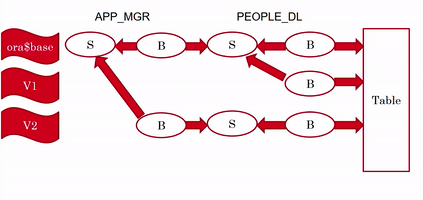
In a previous post I wrote about one misconception about views that is revealed when I talk about Editioning Views in my EBR (Edition-Based Redefinition) presentations.
This post is about another misconception.
In the part of the presentation in which I “preach” to cover every table with an Editioning View and to replace every reference to tables in the code with reference to the corresponding Editioning Views, I usually get the following question from the audience: “but what about DML?”.
Everybody knows that you can SELECT from a view, but there is a misconception that you cannot perform INSERT, UPDATE, MERGE or DELETE statements directly on a view.
So the truth is that (assuming you have been granted the necessary privileges) you can perform DML statements on every view (although it may require some additional work sometimes), except if the view is defined with the WITH READ ONLY clause.
The high-level general rule is that if Oracle can transform the statement to work on actual tables (the view’s base tables), in a consistent and deterministic way, without too much trouble, then we don’t need to do anything else – the view is inherently updatable and the DML statement will succeed. In the rest of the cases, although the view is not inherently updatable, we can “teach” it how to react to DML statements – by defining INSTEAD OF triggers.
Upon view creation Oracle analyzes for each of the view’s columns if it’s inherently updatable, and stores this information in the USER/ALL/DBA_UPDATABLE_COLUMNS dictionary views.
Let’s see some examples.
> create table t (
x number,
y date,
z varchar2(100)
);
Table created.
> create view v as
select x, y, z as an_alias_for_z from t where x>10 order by y;
View created.
> select column_name,updatable,insertable,deletable
from user_updatable_columns
where table_name='V';
COLUMN_NAME UPDATABLE INSERTABL DELETABLE
------------------------------ --------- --------- ---------
X YES YES YES
Y YES YES YES
AN_ALIAS_FOR_Z YES YES YES
3 rows selected.
> insert into v (x,y,an_alias_for_z) values (1,sysdate,'a');
1 row created.
> select * from t;
X Y Z
---------- ------------------- ----------
1 20/06/2016 06:05:12 a
1 row selected.
If the view’s top-level query contains, for example, the DISTINCT operator, then the view is not inherently updatable.
> create or replace view v as
select distinct x, y, z from t;
View created.
> select column_name,updatable,insertable,deletable
from user_updatable_columns
where table_name='V';
COLUMN_NAME UPDATABLE INSERTABL DELETABLE
------------------------------ --------- --------- ---------
X NO NO NO
Y NO NO NO
Z NO NO NO
3 rows selected.
> insert into v (x, y, z) values (2,sysdate,'b');
insert into v (x, y, z) values (2,sysdate,'b')
*
ERROR at line 1:
ORA-01732: data manipulation operation not legal on this view
If a column of the view is defined as an expression, then this column is not inherently updatable, but other “simple” columns are.
> create or replace view v as
select x, y, upper(z) upper_z from t;
View created.
> select column_name,updatable,insertable,deletable
from user_updatable_columns
where table_name='V';
COLUMN_NAME UPDATABLE INSERTABL DELETABLE
------------------------------ --------- --------- ---------
X YES YES YES
Y YES YES YES
UPPER_Z NO NO NO
3 rows selected.
> insert into v (x, y, upper_z) values (3,sysdate,'C');
insert into v (x, y, upper_z) values (3,sysdate,'C')
*
ERROR at line 1:
ORA-01733: virtual column not allowed here
> insert into v (x, y) values (3,sysdate);
1 row created.
> update v set upper_z='C' where x=3;
update v set upper_z='C' where x=3
*
ERROR at line 1:
ORA-01733: virtual column not allowed here
> update v set y=sysdate+1;
2 rows updated.
> select * from t;
X Y Z
---------- ------------------- --------------
3 21/06/2016 06:07:08
1 21/06/2016 06:07:08 a
2 rows selected.
Even columns of a join view – a view with more than one base table in its FROM clause – may be inherently updatable (under some restrictions).
> create table p (
id integer primary key,
name varchar2(100)
);
Table created.
> create table c (
id integer primary key,
p_id integer references p(id),
details varchar2(100)
);
Table created.
> insert into p values (1,'Parent 1');
1 row created.
> insert into p values (2,'Parent 2');
1 row created.
> create or replace view v as
select c.id,c.p_id,c.details,p.name parent_name
from p,c
where p.id = c.p_id;
View created.
> select column_name,updatable,insertable,deletable
from user_updatable_columns
where table_name='V';
COLUMN_NAME UPDATABLE INSERTABL DELETABLE
------------------------------ --------- --------- ---------
ID YES YES YES
P_ID YES YES YES
DETAILS YES YES YES
PARENT_NAME NO NO NO
4 rows selected.
> insert into v(id,p_id,details,parent_name) values (101,1,'Child 1 of parent 1','Parent 1');
insert into v(id,p_id,details,parent_name) values (101,1,'Child 1 of parent 1','Parent 1')
*
ERROR at line 1:
ORA-01776: cannot modify more than one base table through a join view
> insert into v(id,p_id,details) values (101,1,'Child 1 of parent 1');
1 row created.
> update v set parent_name='Parent 8' where id=101;
update v set parent_name='Parent 8' where id=101
*
ERROR at line 1:
ORA-01779: cannot modify a column which maps to a non key-preserved table
> update v set details=upper(details);
1 row updated.
> select * from v;
ID P_ID DETAILS PARENT_NAME
---------- ---------- ------------------------ ---------------------
101 1 CHILD 1 OF PARENT 1 Parent 1
1 row selected.
These are just a few examples. For all the details please see the documentation.
And what about Editioning Views?
Editioning Views are deliberately very limited, because they were designed to allow using them in the code instead of using the base tables.
An Editioning View may contain only the SELECT and FROM clauses, the FROM clause refers to a single table, the SELECT list may contain only columns and aliases (no expressions).
Therefore, by definition, Editioning Views are always inherently updatable.