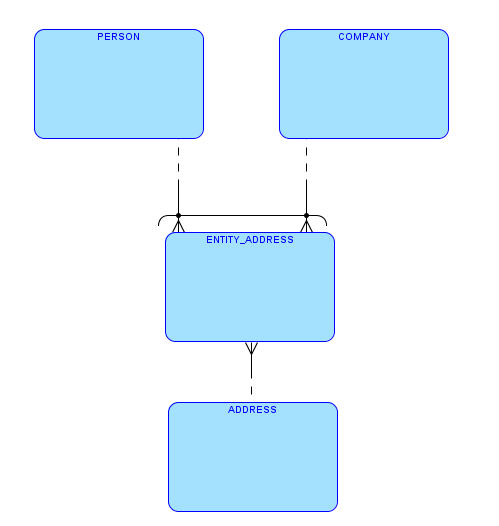
I wrote a post some time ago about implementing arc relationships using virtual columns.
Recently, Toon Koppelaars wrote a detailed and reasoned comment to that post. Since I admire Toon, getting his point of view on something that I wrote is a privilege for me, regardless if he agrees with me or disagrees (and just to be clear, it’s the latter this time). I think that having a public (and civilized) discussion – this time about principles of data modeling and implementation – is a good thing, even if at the end we don’t convince each other.
Therefore I thought Toon’s comment deserves a post of its own. So I’ll quote here everything that he wrote in the comment, with my response after every sentence or paragraph. And everyone is welcome to add their own points of view in the comments section.
I’d like to emphasize that basically I agree with Toon about the general guidelines. What makes life harder, as always, are the nuances, or as we know them well as “it depends”.
And just one general observation first. The starting point of the original post was that the design included an arc. This is the given fact, and my intent was to suggest an implementation for this given fact. I don’t want to put words in your mouth (or keyboard), Toon, but I think that the basis for your arguments is that the arc, as a design concept, is wrong. I think you would prefer to see several entities in the ERD instead of the one with the arc. Am I right in this interpretation?
Toon wrote:
Oren, I just cannot, not comment on this post 😉
And I really appreciate it. Really.
Toon wrote:
Re: Multiple Tables
1) What do you mean by “maintaining another table”? And why is that a disadvantage?
I’ll refer to it after the next paragraph.
Toon wrote:
In my opinion, you should always have a software factory in which the act of introducing a new table is cheap. Why? Because otherwise you end up with database designs with few tables, into which more than few “things” are stored. Which is bad. It’s bad for understandability, it’s bad for performance, it’s bad for future maintenance.
And I completely agree with you.
Toon wrote:
Apparently adding a table is not cheap in your factory?
But, yet, dropping and recreating a CHECK constraint (to involve a new single-char value) is cheap?
As you know me and my database development principles, beliefs and guidelines (for example, here and here), I assume this is a rhetorical question. Of course adding a table is cheap. Actually it is one of the cheapest tasks.
And dropping and recreating a CHECK constraint is not expensive either. It may take some time to VALIDATE it if the table is big, but this is not a reason not to do it. And anyway, if, in order to implement a good design, something is “expensive” (but still realistic), it should not be a reason not to do it (at least, not a good reason).
But, if we have, by design, several tables that are identical – in column names, data types, indexes, constraints – everything except for the table on the other side of the “owner” foreign key, then I start to feel uncomfortable. I get the same feeling that I get when I see two procedures that do the same (or almost the same) thing.
And although many times the arc appears for simple join tables, as in my example, this is not always the case. The entity with the arc may include many columns.
In addition, by “maintaining another table” I did not mean just the CREATE TABLE statement. When a new attribute is added to the designed entity, we need to add a new column – exactly the same column – to all the tables. And the same is true for any change – renaming a column, changing data types, adding or removing constraints, etc.
In my opinion, if I have to repeat the same work over and over instead of doing it just once, I probably do something wrong.
It also reminds me of denormalization. Usually when we talk about denormalization we mean that the same data is kept more than once. I think it’s the same here – just that the duplicate data is kept in the data dictionary tables and not in our schema. And one of the disadvantages of denormalization is that it increases the risk for bugs; in this case, due to a human error we may end up with PERSON_ADDRESSES and COMPANY_ADDRESSESS that are not exactly the same, although they should be.
Toon wrote:
2) Why is the implied code-difference for this solution, more difficult to maintain?
Here I was mainly thinking about lack of reusability.
Toon wrote:
Instead of having these two inserts:
insert into entity_addresses values(AID1,’P’,PID1), and insert into entity_addresses values(AID2,’C’,CID1).You’d have these two:
insert into person_addresses(AID1,PID1), and insert into company_addresses(AID2,CID1).Why is the former “cheaper”?
I was thinking of writing only one INSERT statement:
CREATE OR REPLACE PACKAGE BODY address_mgr AS
PROCEDURE add_entity_address
(
i_address_id IN entity_addresses.address_id%TYPE,
i_owner_type_id IN entity_addresses.owner_type_id%TYPE,
i_owner_id IN entity_addresses.owner_id%TYPE
) IS
BEGIN
INSERT INTO entity_addresses
(address_id,
owner_type_id,
owner_id)
VALUES
(i_address_id,
i_owner_type_id,
i_owner_id);
END add_entity_address;
.
.
.
END address_mgr;
/
Toon wrote:
And this trickles down to all other kinds of SQL statements. Why is:select *
from adresses a
entity_addresses ea
,persons p
where a.id = ea.address_id
and ea.object_type = ‘P’
and ea.object_id = p.person_idapparently easier to write and/or maintain (i.e. cheaper), than:
select *
from adresses a
person_addresses pa
,persons p
where a.id = ea.person_id
and pa.person_id = p.person_id?
I just don’t get that…
Again, I was thinking of a more generic code, rather than duplicating the same code pattern. Something like this:
create type address_t as object (
id integer,
street varchar2(30),
house_number varchar2(10),
city varchar2(30),
country varchar2(30)
)
/
create type address_tt as table of address_t
/
CREATE OR REPLACE PACKAGE BODY address_mgr AS
.
.
.
PROCEDURE get_addresses
(
i_owner_type_id IN entity_addresses.owner_type_id%TYPE,
i_owner_id IN entity_addresses.owner_id%TYPE,
o_addresses OUT address_tt
) IS
BEGIN
SELECT address_t(a.id, a.street, a.house_number, a.city, a.country)
BULK COLLECT
INTO o_addresses
FROM addresses a,
entity_addresses ea
WHERE ea.owner_type_id = i_owner_type_id
AND ea.owner_id = i_owner_id
AND a.id = ea.address_id;
END get_addresses;
.
.
.
END address_mgr;
/
CREATE OR REPLACE PACKAGE BODY person_mgr AS
PROCEDURE get_person
(
i_person_id IN people.id%TYPE,
o_first_name OUT people.first_name%TYPE,
o_last_name OUT people.last_name%TYPE,
o_addresses OUT address_tt
) IS
BEGIN
SELECT p.first_name,
p.last_name
INTO o_first_name,
o_last_name
FROM people p
WHERE p.id = i_person_id;
address_mgr.get_addresses(i_owner_type_id => 'P',
i_owner_id => i_person_id,
o_addresses => o_addresses);
END get_person;
.
.
.
END person_mgr;
/
CREATE OR REPLACE PACKAGE BODY company_mgr AS
PROCEDURE get_company
(
i_company_id IN companies.id%TYPE,
o_name OUT companies.name%TYPE,
o_number_of_employees OUT companies.number_of_employees%TYPE,
o_description OUT companies.description%TYPE,
o_addresses OUT address_tt
) IS
BEGIN
SELECT c.name,
c.number_of_employees,
c.description
INTO o_name,
o_number_of_employees,
o_description
FROM companies c
WHERE c.id = i_company_id;
address_mgr.get_addresses(i_owner_type_id => 'C',
i_owner_id => i_company_id,
o_addresses => o_addresses);
END get_company;
.
.
.
END company_mgr;
/
By the way, we can achieve the same level of code reusability with the “multiple tables” option, by using dynamic SQL instead of static SQL, but I think both of us do not want to go there, do we?
Toon wrote:
To me this alternative (Multiple Tables) *is* the way to deal with the information requirement.
Having entity_adresses, introduces a column in my design (owner_id) whose meaning depends upon the value of another column (owner_type), which is just bad in my opinion.
Isn’t this the case with every composite key, that we need the values of all the columns that compose the key in order to uniquely identify the entity?
Toon wrote:
This alternative also offers the best chances of being able to easily cater for possible future differences in information requirements at the relationship-level. Eg. we may want to track since when a person has had a particular address, but we don’t care for that information requirement in case of companies: you then just add the ‘as-of’ date column to the person_addresses table only, and be done with it.
In my opinion, this becomes a different case. If the entities are not identical in their attributes, I would consider them different entities, and therefore each one deserves its own table. And since I’m not afraid of changing my schema and my code, I would split the generic table into multiple tables only when the need arises.
Toon wrote:
It is the most simple, and easy to understand for others that come join the maintenance team.
Imagine coming in and seeing the table with invisible generated virtual columns that have FK’s on them. Hmmm…
I would probably say: “what a cool idea” 😉