This post is part 8 of the Write Less with More series of blog posts, focusing on new features of Oracle 12c that allow us developers to write less than in previous versions in order to achieve the same functionality. Each part is dedicated for one new feature that solves some common development task. For more details, including the setup of the examples used throughout the series and the list of development tasks that drive the series, please see part 1.
All the Series Parts
Part 1 – write less configuration with SQL*Loader Express Mode
Part 2 – write less application code with Identity Columns
Part 3 – write less application code with In-Database Archiving
Part 4 – write less application code with Temporal Validity
Part 5 – write less code in SQL with Row Limiting
Part 6 – write less “inappropriately located” code with SELECT FROM Package-Level Collection Types
Part 7 – write less code in SQL with Lateral Inline Views
Part 8 – write less “inappropriately located” code with PL/SQL in the WITH Clause
Task #8
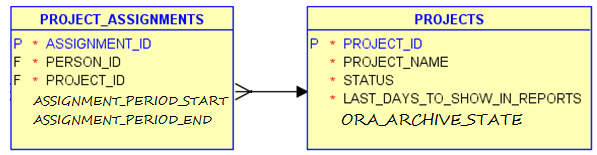
We can write a small function – let’s call it is_date – that gets a string input and checks whether it represents a valid date or not, and then we can call the function from the SELECT statement:
select * from people where is_date(general_info) = 1;
The big question is where to locate the function.
A Pre-12c Solution
So where to locate the function? Before 12c we had only one choice: creating is_date as a stored function (either in a package or standalone), whose scope is the entire schema:
> create or replace function is_date(i_info in varchar2) return number as
l_date date;
begin
if i_info is null then
return 0;
else
l_date := to_date(i_info, 'dd/mm/yyyy');
return 1;
end if;
exception
when others then
return 0;
end is_date;
/
Function created.
> select p.* from people p where is_date(p.general_info) = 1;
PERSON_ID FIRST_NAME LAST_NAME GENERAL_INFO
---------- ---------- --------------- --------------------
102 Paul McCartney 18/6/1942
202 Ella Fitzgerald 15/6/1996
203 Etta James 20/1/2012
But if is_date is used only in the context of this query, storing it and exposing it to the entire schema is quite inappropriate.
A 12c Solution
Oracle 12c offers a better option. The WITH clause can now include not only subquery factoring but also PL/SQL declarations of functions that can be used in the query (and procedures that can be used in those functions). This allows for embedding ad-hoc functions, that are relevant only for a specific SQL statement, in the statement itself. In our case:
> with function is_date(i_info in varchar2) return number as l_date date; begin if i_info is null then return 0; else l_date := to_date(i_info, 'dd/mm/yyyy'); return 1; end if; exception when others then return 0; end is_date; select p.* from people p where is_date(p.general_info) = 1 / PERSON_ID FIRST_NAME LAST_NAME GENERAL_INFO ---------- ---------- --------------- -------------------- 102 Paul McCartney 18/6/1942 202 Ella Fitzgerald 15/6/1996 203 Etta James 20/1/2012
Note: Subquery Factoring is the ability to define some query in the WITH clause, name it, and use this name in the FROM clause of the main query. Before 12c, Subquery Factoring was the only thing you could define in the WITH clause, so “Subquery Factoring” and “the WITH clause” became synonymous. This is probably the reason that now, in 12c, you can hear sometimes the inaccurate statement: “you can define PL/SQL functions in the Subquery Factoring clause”. The correct statement is that “you can define PL/SQL functions in the WITH clause, in addition to Subquery Factoring”.
If you want to learn about many more new features of Oracle 12c, you may be interested in one of my in-house training sessions, particularly the Oracle 12c New Features for Developers full-day seminar.
Recommended Reading: Neil Chandler has utilized this feature nicely in a recent post, by wrapping supplied stored procedures in WITH-level functions.
PL/SQL in SQL in PL/SQL
The PL/SQL language does not support yet the new syntax. If we try to use the previous example as a static SQL statement within a PL/SQL program unit, we’ll get a compilation error:
> create or replace procedure show_date_people as
begin
for l_rec in (
with
function is_date(i_info in varchar2) return number as
l_date date;
begin
if i_info is null then
return 0;
else
l_date := to_date(i_info, 'dd/mm/yyyy');
return 1;
end if;
exception
when others then
return 0;
end;
select p.*
from people p
where is_date(p.general_info) = 1
)
loop
dbms_output.put_line(l_rec.id || ': ' || l_rec.first_name || ' ' || l_rec.last_name);
end loop;
end show_date_people;
/
Warning: Procedure created with compilation errors.
> show err
Errors for PROCEDURE SHOW_DATE_PEOPLE:
LINE/COL ERROR
-------- -----------------------------------------------------------------
4/7 PL/SQL: SQL Statement ignored
5/18 PL/SQL: ORA-00905: missing keyword
6/22 PLS-00103: Encountered the symbol ";" when expecting one of the
following:
loop
We can overcome this limitation by using dynamic SQL instead of static SQL:
> create or replace procedure show_date_people as
l_rc sys_refcursor;
l_id people.person_id%type;
l_first_name people.first_name%type;
l_last_name people.last_name%type;
begin
open l_rc for q''
with
function is_date(i_info in varchar2) return number as
l_date date;
begin
if i_info is null then
return 0;
else
l_date := to_date(i_info, 'dd/mm/yyyy');
return 1;
end if;
exception
when others then
return 0;
end;
select p.person_id,p.first_name,p.last_name
from people p
where is_date(p.general_info) = 1'';
loop
fetch l_rc
into l_id,
l_first_name,
l_last_name;
exit when l_rc%notfound;
dbms_output.put_line(l_id || ': ' || l_first_name || ' ' || l_last_name);
end loop;
close l_rc;
end show_date_people;
/
Procedure created.
> exec show_date_people
102: Paul McCartney
202: Ella Fitzgerald
203: Etta James
PL/SQL procedure successfully completed.
Subqueries
If we use the new syntax in a subquery, and the top-level statement itself is not a SELECT with PL/SQL declarations, it will not work…
> select * from (
with
function is_date(i_info in varchar2) return number
as
l_date date;
begin
if i_info is null then
return 0;
else
l_date := to_date(i_info, 'dd/mm/yyyy');
return 1;
end if;
exception
when others then
return 0;
end is_date;
select p.*
from people p
where is_date(p.general_info) = 1
)
/
with
*
ERROR at line 2:
ORA-32034: unsupported use of WITH clause
unless… we add the WITH_PLSQL hint:
> select /*+ with_plsql */ * from (
with
function is_date(i_info in varchar2) return number
as
l_date date;
begin
if i_info is null then
return 0;
else
l_date := to_date(i_info, 'dd/mm/yyyy');
return 1;
end if;
exception
when others then
return 0;
end is_date;
select p.*
from people p
where is_date(p.general_info) = 1
)
/
PERSON_ID FIRST_NAME LAST_NAME GENERAL_INFO
---------- ---------- --------------- --------------------
102 Paul McCartney 18/6/1942
202 Ella Fitzgerald 15/6/1996
203 Etta James 20/1/2012
Performance Considerations?
Many times when this new feature is discussed, it is presented as a “performance feature”. Indeed, the performance of a query may be improved if instead of calling a stored function it calls an embedded function, since less context switches between the SQL engine and the PL/SQL engine are needed. However, in my opinion, the real strength of this feature is the ability to locate code in the most appropriate location. If a function is needed only in the context of a specific query, then the appropriate location to define this function is in the query itself, rather than littering the schema with a stored function. On the other hand side, if a function is useful for many different queries, then its appropriate location is in the schema level, so it can be defined once and reused by the various queries. In this case, embedding the function implementation in all the queries may have the advantage of performance improvement, but it also has the big disadvantage of code duplication.
If we need to improve the performance of such queries, then, before duplicating the code, we should consider other alternatives – such as scalar subquery cache or the UDF pragma.
Recommended Reading: Martin Widlake has recently wrote a couple of posts about the UDF pragma, including an example for a performance comparison between native SQL, traditional PL/SQL and PL/SQL with the UDF pragma, and an empirical analysis of UDF limitations.
Conclusion
We saw in this part of the Write Less with More series that PL/SQL in the WITH Clause allows us to write less “inappropriately located” code.
I hope you enjoyed the series. This was the last part of it.