Virtual columns were added in Oracle 11g Release 1. We can implement the same concept using views, but one of the advantages that I see in virtual columns is that we can define foreign key constraints on them. Well, we can define foreign key constraints on views as well, but only in DISABLE NOVALIDATE mode, which makes them a decoration rather than a data integrity protector. So to be more precise, we can define enabled foreign key constraints on virtual columns.
This post is about using virtual columns for implementing arc relationships.
In the following ERD, the arc represents the rule “each Entity Address must be owned by either a Person or a Company”:
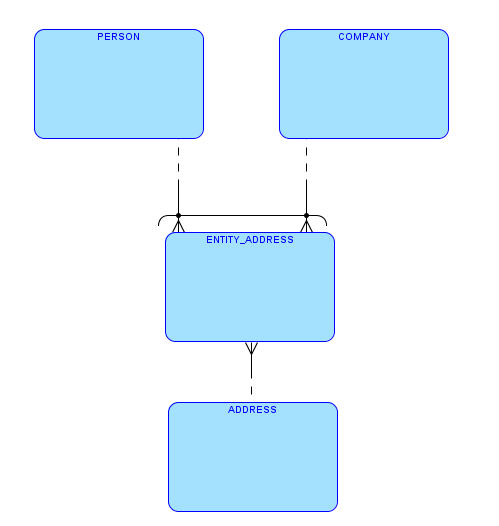
There are three common ways to implement this logical data model.
Multiple Tables
We can split the ENTITY_ADDRESS entity into two tables – say, PERSON_ADDRESSES and COMPANY_ADDRESSES. Disadvantages of this solution are that we need to maintain two (or more) tables and the code parts that manipulate them, although they are very similar. In addition, if later on we need to add another entity to the relationship (for example, Store, in addition to Person and Company) we will have to add another join table – STORE_ADDRESSES – and the relevant code.
A Single Table with Dedicated Columns
We can implement the ENTITY_ADDRESS entity as a single table – say, ENTITY_ADDRESSES – with a dedicated column for each referenced entity – PERSON_ID and COMPANY_ID (in addition to ADDRESS_ID) – and a check constraint to make sure one and only one of the columns PERSON_ID and COMPANY_ID is not null. The disadvantage of this solution is that we still need to maintain the dedicated columns and the code parts that manipulate them, although they are very similar. And if we need to add another entity to the relationship we will have to add another column to the table and to add the relevant code to manipulate the new column.
A Generic Table
We can implement the ENTITY_ADDRESS entity as a single table – say, ENTITY_ADDRESSES – with a generic column for the referenced entity and a column that stores the entity type to which the generic column references – e.g., ADDRESS_ID, OWNER_TYPE_ID, OWNER_ID. The disadvantage of this solution is that we cannot define foreign key constraints from ENTITY_ADDRESSES to the PEOPLE and COMPANIES tables.
Using Virtual Columns
I’d like to suggest another solution, that, using virtual columns, overcomes the above disadvantages.
This solution is based on the generic table one, but we’ll add also a virtual column for each referenced entity. The purpose of the virtual columns is just for enforcing the referential integrity, and the application should not be aware of them. Therefore, if another entity should be added afterwards, we will add another virtual column, but we will have no code changes to make.
Here it is:
> create table people ( > id integer not null primary key, > first_name varchar2(30) not null, > last_name varchar2(30) not null > ); Table created. > create table companies ( > id integer not null primary key, > name varchar2(100) not null, > number_of_employees integer, > description varchar2(1000) > ); Table created. > create table addresses ( > id integer not null primary key, > street varchar2(30), > house_number varchar2(10), > city varchar2(30), > country varchar2(30) > ); Table created.
> create table entity_addresses (
> address_id integer not null references addresses,
> owner_type_id char(1) not null check (owner_type_id in ('P','C')),
> owner_id integer not null,
> --
> primary key (owner_id,owner_type_id,address_id),
> --
> person_id generated always as (decode(owner_type_id,'P',owner_id)) virtual
> constraint address_fk_people references people,
> company_id generated always as (decode(owner_type_id,'C',owner_id)) virtual
> constraint address_fk_companies references companies
> );
Table created.
> insert into people (id,first_name,last_name) values (1,'John','Doe'); 1 row created. > insert into companies (id,name) values (101,'DB Oriented'); 1 row created. > insert into addresses (id,street,city,country) values (1,'Dekel','Zurit','Israel'); 1 row created. > insert into entity_addresses (address_id,owner_type_id,owner_id) > values (1,'P',1); 1 row created. > insert into entity_addresses (address_id,owner_type_id,owner_id) > values (1,'P',101); insert into entity_addresses (address_id,owner_type_id,owner_id) values (1,'P',101) * ERROR at line 1: ORA-02291: integrity constraint (DEMO5.ADDRESS_FK_PEOPLE) violated - parent key not found > insert into entity_addresses (address_id,owner_type_id,owner_id) > values (1,'C',1); insert into entity_addresses (address_id,owner_type_id,owner_id) values (1,'C',1) * ERROR at line 1: ORA-02291: integrity constraint (DEMO5.ADDRESS_FK_COMPANIES) violated - parent key not found > insert into entity_addresses (address_id,owner_type_id,owner_id) > values (1,'C',101); 1 row created.
Hiding the Virtual Columns
Since the virtual columns in this solution are just for enforcing the referential integrity, I prefer to hide them, so adding new entities to the arc (or removing entities from it) will be transparent to the application.
Invisible Columns
In Oracle 12c we can do it by making these columns invisible.
> alter table entity_addresses modify ( > person_id invisible, > company_id invisible > ); Table altered. > select * from entity_addresses; ADDRESS_ID OWN OWNER_ID ---------- --- ---------- 1 P 1 1 C 101
Editioning Views
Being an Edition-Based Redefinition (EBR) evangelist, my application code never refers to tables. Each table is covered by an editioning view, and the application code refers only to views. This practice enables to hide the virtual columns very easily, simply by not including them in the editioning view:
> create editioning view entity_addresses_v as
> select address_id,
> owner_type_id,
> owner_id
> from entity_addresses;
View created.
Unfortunately, EBR is not widely used 🙁
You can, however, use the same idea in non-EBR environment, by creating a regular view rather than an editioning view, and refer to this view from the application code.
Oren, I just cannot, not comment on this post 😉
Re: Multiple Tables
1) What do you mean by “maintaining another table”? And why is that a disadvantage?
In my opinion, you should always have a software factory in which the act of introducing a new table is cheap. Why? Because otherwise you end up with database designs with few tables, into which more than few “things” are stored. Which is bad. It’s bad for understandability, it’s bad for performance, it’s bad for future maintenance.
Apparently adding a table is not cheap in your factory?
But, yet, dropping and recreating a CHECK constraint (to involve a new single-char value) is cheap?
2) Why is the implied code-difference for this solution, more difficult to maintain?
Instead of having these two inserts:
insert into entity_addresses values(AID1,’P’,PID1), and
insert into entity_addresses values(AID2,’C’,CID1).
You’d have these two:
insert into person_addresses(AID1,PID1), and
insert into company_addresses(AID2,CID1).
Why is the former “cheaper”?
And this trickles down to all other kinds of SQL statements. Why is:
select *
from adresses a
entity_addresses ea
,persons p
where a.id = ea.address_id
and ea.object_type = ‘P’
and ea.object_id = p.person_id
apparently easier to write and/or maintain (i.e. cheaper), than:
select *
from adresses a
person_addresses pa
,persons p
where a.id = ea.person_id
and pa.person_id = p.person_id
?
I just don’t get that…
To me this alternative (Multiple Tables) *is* the way to deal with the information requirement.
Having entity_adresses, introduces a column in my design (owner_id) whose meaning depends upon the value of another column (owner_type), which is just bad in my opinion.
This alternative also offers the best chances of being able to easily cater for possible future differences in information requirements at the relationship-level. Eg. we may want to track since when a person has had a particular address, but we don’t care for that information requirement in case of companies: you then just add the ‘as-of’ date column to the person_addresses table only, and be done with it.
It is the most simple, and easy to understand for others that come join the maintenance team.
Imagine coming in and seeing the table with invisible generated virtual columns that have FK’s on them. Hmmm…
Thanks Toon!
I dedicated a new post for your comment and my response to it – http://db-oriented.com//2017/09/30/implementing-arc-relationships-with-virtual-columns-or-not/
Oren.
thanks very much Oren for your effort
this post very useful to me so is linking the benefit from virtual columns using arc relations
i would like to say to mr.Toon that Oreaon give only an example of models , the main target is the link as i mentioned before not discussing the model type chosen by Oreon
any how his is my opinion and thank again Oren
How do we represent that in Oracle Data Modeler?